When building the cryptography layer for a Bitcoin-style blockchain in Rust, the goal should be a small surface area. Every consensus-critical operation passes through it: transaction IDs, block hashes, proof-of-work, signature creation, signature verification, address derivation. Get any of those wrong by a single byte, and nodes diverge. Get the dependency hygiene wrong, and you ship a CVE.
The shape that works: four jobs, four submodules, four dozen lines of public API. That's the entire bitcoin/src/crypto/ directory in this reference implementation — wrapping libraries that have been audited harder than anything you could write yourself: ring (BoringSSL-backed) for SHA-256 and ECDSA, secp256k1 (the same library Bitcoin Core ships) for Schnorr and EC arithmetic, sha2 (pure Rust) for Taproot-style hashing, bs58 for address encoding.
This post walks through each of those four jobs — what the cryptography actually does, why the API is shaped the way it is, and the specific Rust idioms that make it harder to use the layer wrong than to use it right. By the end, if you've written some Rust but never touched cryptography, you should be able to read every line of this layer and know why each one exists.
The dependencies, for reference — these are the only crypto-related crates the layer pulls in:
# bitcoin/Cargo.toml (relevant excerpt)
[dependencies]
ring = "0.17" # SHA-256 + P-256 ECDSA (BoringSSL-backed)
secp256k1 = { version = "0.31", features = ["rand", "global-context"] }
# secp256k1 curve + Schnorr (libsecp256k1 wrapper)
sha2 = "0.10" # Pure-Rust SHA-256 (used for taproot_hash)
bs58 = "0.5" # Base58 / Base58Check encoding
rand = "0.9" # OS-backed RNG, supplied to sign_schnorr_with_rng
Four crates. Roughly three thousand lines of Rust on top of them. That's the entire perimeter of cryptographic code you need to keep correct.
The Four Jobs
A blockchain implementation needs cryptography to answer three practical questions: how to name things, how to prove authorization, and how to represent these ideas as bytes humans can copy/paste. Split that into four submodules:
| Module |
Job |
Public API |
hash |
turn arbitrary bytes into stable identifiers |
sha256_digest, taproot_hash |
signature |
prove a private-key holder authorized a message |
schnorr_sign_digest, schnorr_sign_verify |
keypair |
generate secrets and derive their public counterparts |
new_schnorr_key_pair, get_schnorr_public_key |
address |
encode/decode binary payloads into typeable strings |
base58_encode, base58_decode |
The mod.rs is short on purpose — it defines what the rest of the codebase is allowed to call, and nothing else:
pub mod address;
pub mod hash;
pub mod keypair;
pub mod signature;
pub use address::{base58_decode, base58_encode};
pub use hash::{sha256_digest, taproot_hash};
pub use keypair::{get_schnorr_public_key, new_key_pair, new_schnorr_key_pair};
pub use signature::{
ecdsa_p256_sha256_sign_digest,
ecdsa_p256_sha256_sign_verify,
schnorr_sign_digest,
schnorr_sign_verify,
};
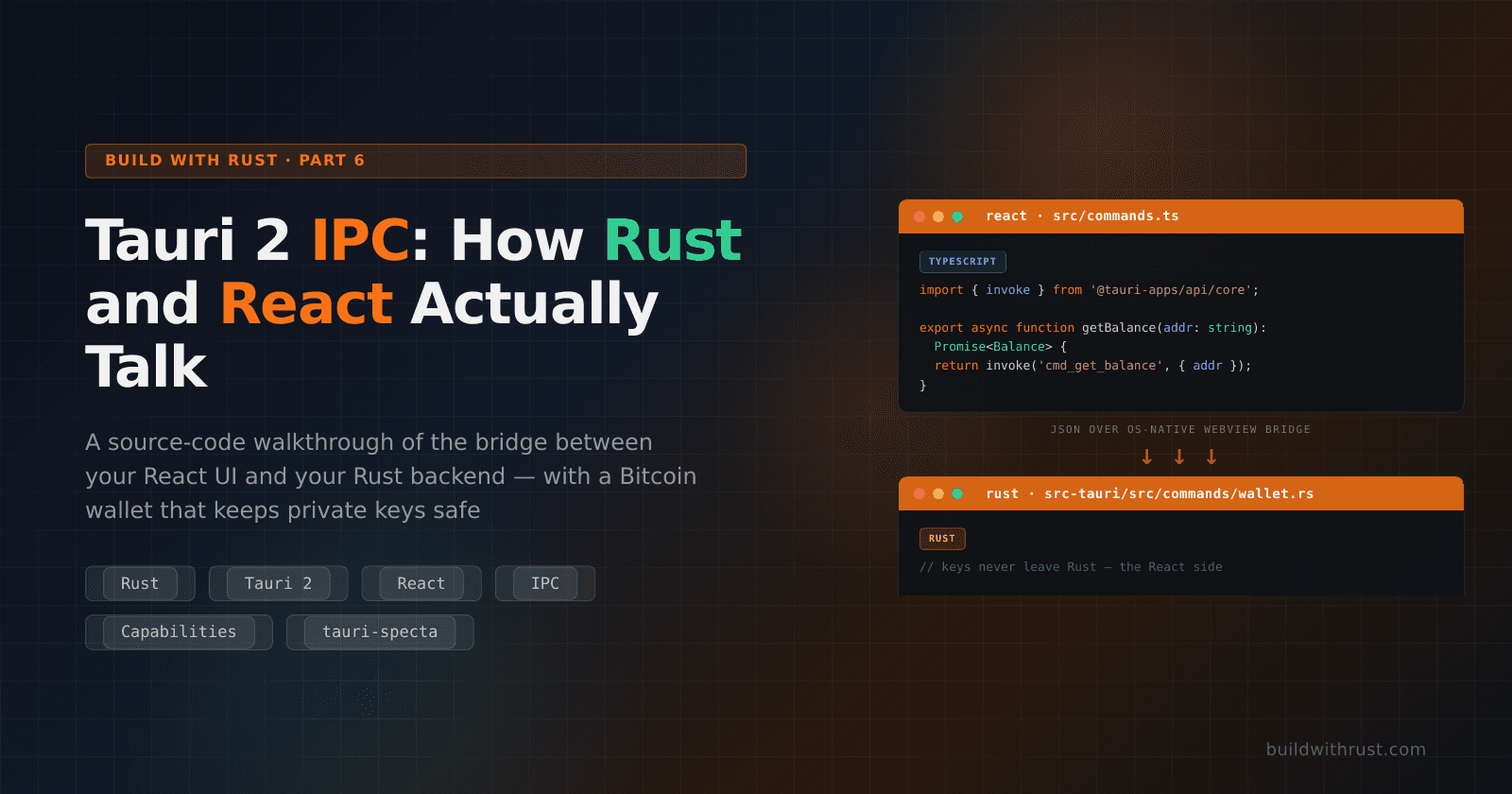
Because bitcoin/src/lib.rs re-exports the crypto module (pub use crypto::*;), call sites elsewhere in the crate look like crate::sha256_digest(bytes) — short, visible, easy to grep for, and with the cryptographic decisions still centralized in one place.
Hashing: The Workhorse
A hash function is a one-way compression function that turns any input bytes into a fixed 32-byte output ("digest"). In a blockchain, hashes do four jobs: they identify transactions, they link blocks together, they drive proof-of-work, and they let nodes agree on what they're looking at without having to compare megabytes of state.
A blockchain relies on five SHA-256 properties:
- Determinism: same input, same output — every node, every machine, forever.
- Preimage resistance: given
h = SHA256(m), recovering m is computationally infeasible.
- Second-preimage resistance: given
m, finding a different m' with the same hash is infeasible.
- Collision resistance: finding any two distinct inputs with the same hash is infeasible — the cost is ~2¹²⁸ hash evaluations, not 2²⁵⁶, because of the birthday paradox (the fastest collision attack only needs to search half the bits before two random outputs collide on average).
- Avalanche: flipping 1 input bit flips ~50% of output bits.
That last property is the one that does the heavy lifting for tamper-evidence. If a node receives a block claiming to be the Genesis but with one byte modified, the hash won't just be "close" to the expected hash — it will be utterly different, and the chain link from the next block won't point to it anymore.

The implementation is twelve lines:
use ring::digest::{Context, SHA256};
pub fn sha256_digest(data: &[u8]) -> Vec<u8> {
let mut context = Context::new(&SHA256);
context.update(data);
let digest = context.finish();
digest.as_ref().to_vec()
}
Reach for ring because it's a thin wrapper over BoringSSL — the same C cryptographic core that runs production traffic at Google. The Context API is incremental (you can call update repeatedly with chunks), which is useful for hashing large data without materializing it all in memory. The blockchain's hash sites don't need that, but the cost of supporting it is zero.
Where hashing shows up
The sha256_digest function gets called in three structurally important places:
Transaction IDs. A transaction's identity is the hash of its content. But there's a chicken-and-egg problem: the hash depends on the bytes, and the ID is one of the fields in the transaction. The fix is to hash a trimmed copy with the ID field cleared:
fn hash(&mut self) -> Result<Vec<u8>> {
let tx_copy = Transaction {
id: vec![], // exclude from the bytes being hashed
vin: self.vin.clone(),
vout: self.vout.clone(),
};
Ok(sha256_digest(tx_copy.serialize()?.as_slice()))
}
Then store the result into the transaction's id field. The hash of any transaction is fully determined by its inputs and outputs — change any byte of either, and the ID changes.
Proof-of-work loops. PoW is "try nonces until the hash is below a target." It's just sha256_digest running in a loop, hammering through nonces:
loop {
let candidate_bytes = serialize_header(&header_with_nonce);
let hash = sha256_digest(&candidate_bytes);
if hash_int(&hash) < target { // big-endian compare against
return (nonce, hash); // a 256-bit difficulty target
}
nonce = nonce.wrapping_add(1); // wrap on overflow, never panic
}
hash_int interprets the 32-byte digest as a 256-bit big-endian integer so it can be compared against the difficulty target — small numerical value means many leading zero bits, which means many failed hashes had to come before this one. wrapping_add(1) is the Rust-specific touch: integer overflow on nonce += 1 would panic in debug builds, which is fatal in a tight CPU loop. Wrapping arithmetic is well-defined and correct here because the absolute value of the nonce doesn't matter — only that it changes between attempts.
The asymmetry here is what makes PoW work: mining requires millions of hash evaluations on average; verification requires one. Every receiving node validates the same nonce-hash pair with a single sha256_digest call.
Block-level transaction commitment. A block needs a single fingerprint of all its transactions. Bitcoin uses a Merkle tree — a binary tree where each leaf is a transaction hash, each internal node is the hash of its two children concatenated, and the root is the single hash committing to every transaction in the block. The benefit of the tree shape is that you can prove a single transaction is in the block by showing only log₂(n) sibling hashes (the path from leaf to root), which is what light clients and SPV wallets rely on. A teaching codebase can get away with a simpler hash-of-concatenated-IDs:
pub fn hash_transactions(&self) -> Vec<u8> {
let mut txhashs = vec![];
for transaction in &self.transactions {
txhashs.extend(transaction.get_id());
}
crate::sha256_digest(txhashs.as_slice())
}
This is one of the explicit simplifications worth flagging. It costs O(n) bytes to compute (vs. O(n) hashes for a Merkle tree, but with Merkle's per-tx inclusion proofs as the upgrade path). For a teaching codebase that's the right trade-off; for byte-for-byte Bitcoin compatibility, build a real Merkle root.
There's also a second SHA-256 entry point, taproot_hash, that uses the pure-Rust sha2 crate instead of ring. The output is identical — same algorithm, different implementation — and the split is historical: this codebase started with ring for general hashing, then added sha2 when Taproot-style address derivation got wired in and a no-C-dependency path was needed in the hot path. In production you'd probably consolidate; for a learning codebase, having both paths visible is instructive.
Note: Bitcoin Core uses double SHA-256 (SHA256(SHA256(x))) for many identifiers. This codebase uses single SHA-256 for clarity. That's consensus-relevant — for byte-for-byte Bitcoin compatibility, the hashing rules have to be aligned. Call it out explicitly rather than hiding it.
Signatures: Schnorr Over secp256k1
A digital signature is a mathematical proof that someone who knows a private key approved a specific sequence of bytes. Without revealing the key. It provides three things: authenticity ("the holder of this key authorized this message"), integrity ("if the message changes, verification fails"), and unforgeability ("you can't make a valid signature without the key").
Bitcoin historically used ECDSA over secp256k1. Modern Bitcoin (Taproot, BIP-340) uses Schnorr over the same curve. Schnorr signatures are smaller (always 64 bytes vs. ECDSA's variable 70–72), have provably stronger security under standard assumptions, and they support signature aggregation — multiple signers can produce one combined signature, which is what makes Taproot's spending paths so powerful.
For a new implementation, pick Schnorr as the primary path. ECDSA helpers can stick around for contrast (and to show how ring's API differs).
Signing
use secp256k1::{Keypair, Secp256k1, SecretKey};
pub fn schnorr_sign_digest(
private_key: &[u8],
message: &[u8],
) -> Result<Vec<u8>> {
let secp = Secp256k1::new();
let secret_key_array: [u8; 32] = private_key
.try_into()
.map_err(|_| BtcError::TransactionSignatureError(
"Invalid private key length".to_string()
))?;
let secret_key = SecretKey::from_byte_array(secret_key_array)?;
let message_hash = sha256_digest(message);
let keypair = Keypair::from_secret_key(&secp, &secret_key);
let mut rng = rand::rng();
let signature = secp.sign_schnorr_with_rng(
&message_hash,
&keypair,
&mut rng,
);
Ok(signature.as_ref().to_vec())
}
A few things worth noticing in those twenty lines:
Length validation is enforced by the type system, not by an if statement. private_key.try_into() returns Result<[u8; 32], _> — if the slice isn't exactly 32 bytes, the error maps to a BtcError and the function returns early. There is no path through this function where a 31-byte or 33-byte input gets silently accepted.
The message is hashed inside the signing function. Schnorr conceptually signs a 32-byte digest, not arbitrary-length data. So always feed in SHA256(message). Callers can pass whatever bytes they want — for transactions, that's the trimmed-copy hash — and the function does the right thing.
Randomness is supplied at sign time. Schnorr is technically deterministic in the BIP-340 spec, but the secp256k1 crate's API takes an RNG and uses it to build a nonce. Pass rand::rng(), which delegates to the OS. Never seed your own RNG for cryptographic operations — the OS entropy pool is better than anything you can build in user space.
The signature is always 64 bytes, regardless of the message size or the key. Predictable output sizes simplify storage, serialization, and on-the-wire framing.
Verification
pub fn schnorr_sign_verify(
public_key: &[u8],
signature: &[u8],
message: &[u8],
) -> bool {
let secp = Secp256k1::new();
let public_key_array: [u8; 33] = match public_key.try_into() {
Ok(arr) => arr,
Err(_) => return false,
};
let pk = match PublicKey::from_byte_array_compressed(public_key_array) {
Ok(pk) => pk,
Err(_) => return false,
};
// Schnorr verifies against an x-only (32-byte) public key,
// not the 33-byte compressed form.
let pk_bytes = pk.serialize();
let xonly_array: [u8; 32] = match pk_bytes[1..33].try_into() {
Ok(arr) => arr,
Err(_) => return false,
};
let xonly_pk = match XOnlyPublicKey::from_byte_array(xonly_array) {
Ok(pk) => pk,
Err(_) => return false,
};
let message_hash = sha256_digest(message);
let signature_array: [u8; 64] = match signature.try_into() {
Ok(arr) => arr,
Err(_) => return false,
};
let sig = schnorr::Signature::from_byte_array(signature_array);
secp.verify_schnorr(&sig, &message_hash, &xonly_pk).is_ok()
}
The verifier's signature-input parsing is paranoid by design — every malformed input path returns false, never a panic. A malicious peer can ship a transaction with a 17-byte signature or a 5-byte public key, and the verification function will reject it cleanly without taking the node down. Returning false for a malformed signature is equivalent to "the signature doesn't verify," which is correct: an unparseable signature is not a valid signature.
The conversion from compressed (33-byte) to x-only (32-byte) public key is Schnorr-specific. Compressed public keys carry a 1-byte parity prefix (0x02 or 0x03) plus 32 bytes of X coordinate. Schnorr verification only needs the X coordinate — Y is implicit — so the prefix gets stripped.
How signing and verification thread through the transaction code
Signing and verifying transactions ties everything together. Both sides reconstruct the same trimmed copy of the transaction, hash it, then sign or verify against that hash. The trick is reconstruction: the verifier doesn't have the signer's draft, just the final transaction with signatures attached, but they can rebuild the exact bytes that were signed by clearing the signature fields and copying in each input's pub-key hash.
A short detour on field naming, because the next code listing reuses one field for two purposes and that's worth flagging up front. A TXInput has both a pub_key field and a signature field. During signing/verification, the input's pub_key field is briefly repurposed to hold the previous output's pub_key_hash so it gets included in the hashed bytes — this is a Bitcoin convention going back to the original whitepaper, and it's how the verifier knows which output's lock the signature was meant to satisfy. After hashing, the field gets cleared again so the bytes don't leak into later inputs' hashes within the same transaction.

The signing side, called once per input:
async fn sign(
&mut self,
blockchain: &BlockchainService,
private_key: &[u8],
) -> Result<()> {
let mut tx_copy = self.trimmed_copy();
for (idx, vin) in self.vin.iter_mut().enumerate() {
// 1. Find the previous transaction being spent from.
let prev_tx = blockchain
.find_transaction(vin.get_txid())
.await?
.ok_or_else(|| BtcError::TransactionNotFoundError(
"Previous transaction not found".to_string(),
))?;
// 2. Splice the prev-output's pub_key_hash into the trimmed copy.
tx_copy.vin[idx].signature = vec![];
tx_copy.vin[idx].pub_key = prev_tx.vout[vin.vout].pub_key_hash.clone();
tx_copy.id = tx_copy.hash()?;
tx_copy.vin[idx].pub_key = vec![];
// 3. Sign the resulting transaction hash.
let signature = schnorr_sign_digest(private_key, tx_copy.get_id())?;
vin.signature = signature;
}
Ok(())
}
And the verifier, structurally identical:
pub async fn verify(&self, blockchain: &BlockchainService) -> Result<bool> {
if self.is_coinbase() {
return Ok(true);
}
let mut trimmed = self.trimmed_copy();
for (idx, vin) in self.vin.iter().enumerate() {
let prev_tx = blockchain
.find_transaction(vin.get_txid())
.await?
.ok_or_else(|| BtcError::TransactionNotFoundError(
"Previous transaction not found".to_string(),
))?;
trimmed.vin[idx].signature = vec![];
trimmed.vin[idx].pub_key = prev_tx.vout[vin.vout].pub_key_hash.clone();
trimmed.id = trimmed.hash()?;
trimmed.vin[idx].pub_key = vec![];
if !schnorr_sign_verify(
vin.get_pub_key(),
vin.get_signature(),
trimmed.get_id(),
) {
return Ok(false);
}
}
Ok(true)
}
A few worth-noticing details:
is_coinbase() short-circuits to Ok(true). A coinbase transaction is the special transaction that creates new coins as the block's mining reward. It has no real inputs to spend from (the protocol-specified pseudo-input doesn't reference any previous output), so there's nothing to verify a signature against. The miner who built the block is implicitly authorized by the proof-of-work consumed.- The return type is
Result<bool>, not bool. The two possible outcomes are conceptually different: Ok(true) / Ok(false) mean "the signature was successfully checked and did/didn't verify"; Err(...) means "verification couldn't even be attempted because the previous transaction wasn't found in the local chain." The caller treats those very differently — a missing prev-tx is a sync issue, while a failed verification is a protocol violation.
- No
? inside the verification check. schnorr_sign_verify returns bool, so the code uses if !... rather than ?. This is intentional: a malformed signature is not an error in the program-flow sense, it's just an invalid input to a check that always answers true or false.
Notice how mechanical the verifier is. There is no oracle, no external trust, no shared secret. The verifier just replays the same byte-construction that the signer ran, and checks that the attached signature matches the resulting hash. Determinism is what gives the network consensus on which transactions are valid, even though the creation of those transactions is wildly distributed.
Keys: Generating Secrets and Deriving Their Public Halves
A private key on secp256k1 is, fundamentally, a 32-byte random number — specifically, an integer in the range [1, n) where n is the curve order, ~2²⁵⁶ − 2¹²⁸. Practically, that means almost every random 32-byte value is a valid private key (the exclusion zone near the top of the range and the value 0 together cover about 2¹²⁸ out of 2²⁵⁶ possible values, so the probability of generating an invalid key by chance is negligible). Generating one looks like this:
pub fn new_schnorr_key_pair() -> Result<Vec<u8>> {
let mut secret_key_bytes = [0u8; 32];
ring::rand::SystemRandom::new()
.fill(&mut secret_key_bytes)
.map_err(|e| BtcError::WalletKeyPairError(e.to_string()))?;
// Round-trip through SecretKey to validate that the bytes
// form a valid scalar (rejects 0 and any value above the curve order).
let secret_key = SecretKey::from_byte_array(secret_key_bytes)
.map_err(|e| BtcError::WalletKeyPairError(e.to_string()))?;
Ok(secret_key.secret_bytes().to_vec())
}
Two operations, both important:
SystemRandom::new().fill(...) asks the OS for cryptographically secure random bytes — /dev/urandom on Linux, BCryptGenRandom on Windows. The OS entropy pool aggregates timing jitter, hardware events, and (on modern CPUs) RDRAND instructions. Anything user-space can build is a downgrade.SecretKey::from_byte_array validates the candidate bytes. Not every 32-byte value is a valid secp256k1 scalar — zero is not (it would produce the point at infinity, which is the curve's "identity element" and doesn't represent a usable public key), and values ≥ the curve order would wrap around modulo n and silently degrade the security argument. The constructor rejects both, returning an error rather than silently corrupting the key.
The public key is derived by elliptic-curve scalar multiplication of the private key by the curve's generator point G. Mechanically: take a fixed publicly-known point on the curve (G), and "add it to itself" priv_key times following the curve's addition rule. That gives a new point on the curve — the public key. The addition rule is geometric (draw a line through two points, find the third intersection with the curve, reflect across the X-axis), but the implementation is pure integer arithmetic modulo the curve's prime field. Three things make this useful for cryptography:
- Forward computation is fast. With double-and-add, computing
priv_key · G takes ~256 doublings and ~128 additions — sub-millisecond.
- Backward computation is intractable. Recovering
priv_key from priv_key · G is the elliptic-curve discrete logarithm problem — there is no known algorithm faster than ~2¹²⁸ operations on secp256k1. That's the security foundation for every Bitcoin signature ever made.
- The output is small. A point on the curve is just two coordinates, each 32 bytes. As shown in a moment, that compresses to 33 bytes total.
The Rust call is one line:
pub fn get_schnorr_public_key(private_key: &[u8]) -> Result<Vec<u8>> {
let secp = Secp256k1::new();
let secret_key_array: [u8; 32] = private_key
.try_into()
.map_err(|_| BtcError::WalletKeyPairError(
"Invalid private key length".to_string()
))?;
let secret_key = SecretKey::from_byte_array(secret_key_array)?;
let public_key = PublicKey::from_secret_key(&secp, &secret_key);
Ok(public_key.serialize().to_vec())
}
The output is a 33-byte compressed public key — a single prefix byte (0x02 if the Y coordinate is even, 0x03 if odd) followed by the 32-byte X coordinate. The Y coordinate is implied by the prefix and the curve equation, saving 32 bytes per key vs. the uncompressed form. Bitcoin standardized on compressed keys for exactly this reason: storage and bandwidth scale with the size of the key, and over millions of transactions the savings add up.
The full wallet creation flow chains three crypto operations into a typeable address:

Every arrow on that diagram is computationally cheap going right and infeasible going left — the same one-way property described in the discrete-log point above. Even if an attacker has your address, they can't work back to your public key (it's hashed); even if they had the public key, they couldn't work back to the private key (discrete log).
A note on ECDSA helpers
The crypto layer also exposes ECDSA signing and verification, but they're not on the active path:
pub fn ecdsa_p256_sha256_sign_digest(
pkcs8: &[u8],
message: &[u8],
) -> Result<Vec<u8>> {
let rng = ring::rand::SystemRandom::new();
let key_pair = EcdsaKeyPair::from_pkcs8(
&ECDSA_P256_SHA256_FIXED_SIGNING,
pkcs8,
&rng,
)?;
let signature = key_pair.sign(&rng, message)?;
Ok(signature.as_ref().to_vec())
}
Two things are different from the Schnorr path. First, the key is in PKCS#8 format — a standardized, slightly heavier wire format that includes algorithm metadata. Useful for interoperating with non-Bitcoin systems; unnecessary for a Bitcoin-style chain. Second, the curve is P-256 (secp256r1), not Bitcoin's secp256k1. They look similar — both 256-bit curves over a prime field — but they have different parameters and are not interchangeable. Real Bitcoin ECDSA would be ECDSA over secp256k1, which the secp256k1 crate also supports.
Keep the ECDSA helpers as a reference comparison point and as an entry hook for anyone who wants to wire secp256k1-flavored ECDSA in for legacy Bitcoin compatibility. They're a useful contrast: same conceptual operation (sign a message with a key), wildly different ergonomics.
Addresses: Bytes Humans Can Safely Copy/Paste
A wallet address isn't a key. It's a human-friendly encoding of a binary payload — usually version_byte || pub_key_hash || 4_byte_checksum — that's been serialized into a string a person can type or paste into a chat without losing characters.
Why not just use hex? Two reasons:
- Hex is verbose. A 25-byte payload becomes 50 hex characters. Base58 brings that down to ~34 characters.
- Hex has confusable characters.
0 vs O, 1 vs l vs I — easy to mistype, hard to spot. Base58 is the alphabet [A-HJ-NP-Za-km-z1-9] — no zero, no capital O, no capital I, no lowercase L. Anything that survives Base58 decoding looks unambiguous.
The encoding/decoding pair lives in crypto/address.rs and wraps the bs58 crate:
use bs58;
pub fn base58_encode(data: &[u8]) -> String {
bs58::encode(data).into_string()
}
pub fn base58_decode(data: &str) -> Result<Vec<u8>> {
Ok(bs58::decode(data)
.into_vec()
.map_err(|e| BtcError::Base58DecodeError(e.to_string()))?)
}
That's the whole module. The functions are tiny because the actual Base58 alphabet handling is in bs58 — the wrapper just provides the right error type at the boundary.
What about the checksum? In Bitcoin's full Base58Check format, the address is built as:
payload = version_byte || pub_key_hash (1 + 20-32 bytes)
checksum = SHA256(SHA256(payload))[0..4] (4 bytes)
address_bytes = payload || checksum (25-37 bytes)
address_string = base58_encode(address_bytes) (~34-44 chars)
The checksum gives you typo detection: if you mistype one character of an address, the recomputed checksum almost certainly won't match the four bytes embedded at the end, and the wallet rejects the address before it can send funds to a black hole. This is why Bitcoin addresses fail loudly on a typo instead of just sending money to nowhere.
The raw base58_encode / base58_decode exposed here are the building blocks. The full Base58Check assembly (version byte + checksum + concatenation) belongs in the wallet layer rather than the crypto layer, because the version byte choice depends on the address type (legacy P2PKH, SegWit, Taproot — each has its own version) and the crypto module shouldn't take a position on which one. Separation of concerns: the crypto module knows how to encode bytes; the wallet knows what bytes mean.
The crypto layer doesn't run in a vacuum. Every node that processes a block does the same crypto work — and an active attacker controls the network, can send malformed inputs, and may be measuring timing to extract bits of your secrets. Five practices make the difference between "looks fine in tests" and "doesn't get owned in production":
Use the OS RNG. Always. ring::rand::SystemRandom for everything random in this layer. There is no scenario in a blockchain context where seeding your own PRNG is correct.
Validate inputs before they touch crypto state. Length checks in particular. The try_into::<[u8; N]>() pattern enforces this at the type level — there's literally no way past it with a wrong-sized slice. Use it everywhere bytes come in from outside the crate.
Return Result, never panic, on cryptographic operations. A panic on malformed input becomes a denial-of-service vector — any peer who can ship a 31-byte signature can crash the node. Every public function in crypto/ should return Result<T, BtcError> or bool. None of them should unwrap.
Trust the constant-time implementations the libraries give you. "Constant-time" means the runtime of an operation does not depend on the secret it's manipulating. The reason this matters: if your signature verification finishes faster when the first byte of the key happens to be zero, an attacker who can run thousands of verifications on a server (or measure power draw, or measure cache misses, or any other "side channel") can reconstruct the secret bit by bit. This is not theoretical — Bleichenbacher's RSA attacks and the various Lucky13/timing attacks against TLS were all exactly this. Both ring and secp256k1 (the C library libsecp256k1 underneath) are explicitly constant-time on the hot paths. Hand-rolling constant-time crypto is famously easy to get wrong — even comparing two byte slices with == is a timing leak. Delegate.
Treat private keys as toxic. No logging. No serialization in plaintext. No leaving them in memory longer than needed. In a production wallet, private keys live in an SQLCipher-encrypted SQLite database; in transit through the API they exist as Vec<u8> with deliberately minimal lifetime. Rust's ownership model helps — the borrow checker won't let you accidentally hand a &SecretKey to a logging facility — but discipline matters. For very high-value keys, zeroize on drop and hardware-backed key stores are the next steps up.
On a modern x86-64 server core, with the ring and secp256k1 libraries:
| Operation |
Throughput |
Per-op latency |
sha256_digest (small input) |
~1.5 GB/s |
<1 µs |
| Schnorr signing |
1,000–2,000 ops/s |
0.5–1 ms |
| Schnorr verification |
2,000–4,000 ops/s |
0.25–0.5 ms |
| Public key derivation |
5,000–10,000 ops/s |
0.1–0.2 ms |
| Key generation (incl. RNG) |
100–200 ops/s |
5–10 ms |
The bottleneck for transaction throughput is signature verification — at 2,000–4,000 verifications per second per core, a busy node spends most of its CPU on verify_schnorr. In practice, for high-throughput nodes you'd want batch verification (secp256k1 supports it natively) and you'd parallelize across cores with rayon. Both are off-the-shelf.
Try it Yourself
Drop this into a fresh cargo new --bin crypto_demo and add the four crates from the dependencies block at the top of this post. The whole sign-and-verify roundtrip is fewer than 30 lines:
use bitcoin::crypto::{
sha256_digest,
new_schnorr_key_pair,
get_schnorr_public_key,
schnorr_sign_digest,
schnorr_sign_verify,
};
fn main() -> anyhow::Result<()> {
// 1. Generate a fresh key pair
let private_key = new_schnorr_key_pair()?;
let public_key = get_schnorr_public_key(&private_key)?;
println!("priv: {} bytes pub: {} bytes",
private_key.len(), public_key.len());
// → priv: 32 bytes pub: 33 bytes
// 2. Sign a message
let message = b"Hello, blockchain!";
let signature = schnorr_sign_digest(&private_key, message)?;
println!("sig: {} bytes", signature.len()); // → sig: 64 bytes
// 3. Verify (happy path)
let ok = schnorr_sign_verify(&public_key, &signature, message);
assert!(ok, "valid signature must verify");
// 4. Verify (tampered message — must fail)
let tampered = b"Hello, blockchain?";
let bad = schnorr_sign_verify(&public_key, &signature, tampered);
assert!(!bad, "tampered message must NOT verify");
// 5. Show the avalanche effect on a 1-byte change
println!("hash(orig) = {:x?}", &sha256_digest(message)[..8]);
println!("hash(tampered) = {:x?}", &sha256_digest(tampered)[..8]);
Ok(())
}
Two things you'll observe:
- The valid signature verifies; the tampered-message verification returns
false cleanly — no panic, no error, just false. That's the API working as designed.
- The hashes of the two messages share zero bytes in common despite a single character difference. That's the avalanche effect in action.
Key Takeaways
If you take five things away from this layer, take these:
Keep the cryptographic surface area small. Four submodules, ten public functions. Anyone reading the code can audit exactly what's exposed. Anyone adding a new cryptographic operation has to do it in one place. Cryptographic agility comes from a small, deliberate API, not from hiding choices behind wrappers.
Length validation through the type system, not through assertions. private_key.try_into::<[u8; 32]>() turns "is this the right length?" from a runtime question with a panic-on-wrong-answer into a compile-time-checked Result. Use it everywhere you accept bytes from outside the crate.
Sign and verify must reconstruct the same byte sequence. The trimmed-copy pattern works because both sides do the same thing in the same order. A single byte of disagreement — different field order, different encoding, an extra newline — and verification fails. Lock down your serialization choices and don't let them drift.
Trust audited libraries. Don't reinvent crypto. ring, secp256k1, and sha2 are the libraries to pick. They've been hammered on by people who specialize in finding cryptographic bugs. A cryptography layer should be mostly plumbing between them and the rest of the codebase, plus type-level guarantees that the plumbing can't leak. The actual hashing and signing bodies are someone else's problem, and that's a feature.
Performance is dominated by verification. Plan for it. Mining is parallel. Signing is per-user, slow but rare. Verification is per-transaction, must run on every node, and is where >80% of crypto time goes in a busy chain. Batch where you can. Parallelize where you must.
Explore the Source Code
The complete cryptography layer is open source:
Full repository: github.com/bkunyiha/rust-blockchain
Key files referenced in this post:
This post is adapted from Rust Blockchain: A Full-Stack Implementation Guide — a 33-chapter book covering Axum, Iced, Tauri 2, Tokio, SQLCipher, Docker, and Kubernetes through one cohesive project.
Available now on Amazon (paperback + Kindle + hardcover), Gumroad (PDF + EPUB), and Leanpub (pay what you want).
Free resource: Clone the Starter Template
Follow buildwithrust.com for weekly posts on building production systems in Rust.