Async Rust with Tokio: Building P2P Blockchain Networking
Production concurrency patterns from a full-stack blockchain node built in Rust
Async Rust with Tokio: Building P2P Blockchain Networking
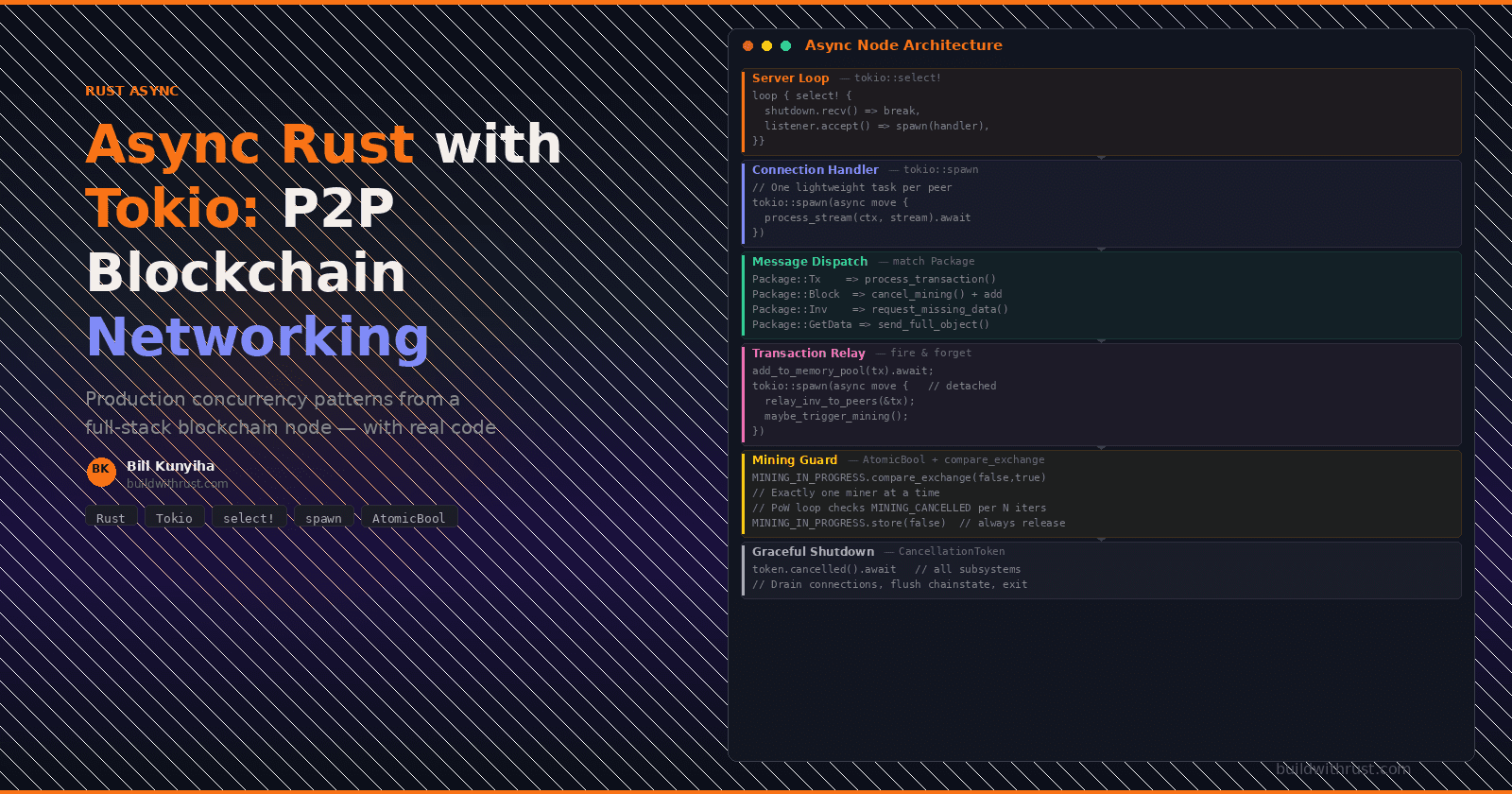
We built a peer-to-peer networking layer for a Bitcoin-style blockchain node using Tokio, Rust's async runtime. The node accepts inbound TCP connections from peers, dispatches different message types to different subsystems, relays transactions and blocks across the network, runs proof-of-work mining that can be cancelled mid-computation, and shuts down gracefully on Ctrl+C — all concurrently, without any of these activities blocking the others.
This post walks through the concurrency patterns we used, with real code from the project. These patterns — select! for event multiplexing, spawn for per-connection isolation, atomic flags for cross-task coordination, and spawn_blocking for bridging sync and async worlds — transfer directly to any async Rust system that coordinates multiple independent subsystems.
What a Blockchain Node Must Do Concurrently
A blockchain node isn't a request-response server. It's a peer in a network where every participant is both client and server simultaneously. At any given moment, our node might be:
Accepting inbound TCP connections from peers who want to announce new blocks or transactions
Dispatching messages — routing each inbound packet to the right handler (chainstate, mempool, peer discovery)
Relaying inventory — broadcasting transaction and block hashes to every connected peer
Mining a block — running proof-of-work computation that could take seconds or minutes
Cancelling mining — if a competing block arrives from a peer while we're still computing, we need to stop immediately
Responding to API queries — the web UI and wallet apps ask for blockchain height, balances, and transaction history
Shutting down cleanly — releasing the TCP port, flushing state, without corrupting the chain database
Each of these is a concurrent activity that can't block the others. Tokio gives us the primitives to express this, but the composition is where the real engineering happens.
The Mental Model: Async, Parallel, or Both?
Before diving into code, it's worth getting precise about terminology that even experienced developers conflate. These distinctions directly affect which Tokio primitives you reach for at each point in the blockchain node.
Concurrency vs Parallelism
Concurrency means multiple tasks make progress over the same time period. They might interleave on a single core (one runs while another waits for I/O), or they might truly execute simultaneously on separate cores.
Parallelism is a subset of concurrency where multiple tasks execute at the same instant on different CPU cores.
A blockchain node needs both. Network I/O (waiting for a peer to send a message) is concurrent but doesn't need parallelism — the CPU is idle during the wait, so interleaving is efficient. Mining (computing SHA-256 hashes in a tight loop) is CPU-bound and benefits from parallelism — it actually uses a core continuously.
Async Rust with Tokio gives you concurrency by default. Parallelism comes from Tokio's multi-threaded runtime, which schedules tasks across multiple OS threads. But here's the subtlety: a single async task is never parallel with itself. It runs on one thread at a time and can only be "elsewhere" when it's suspended at an .await point. True parallelism only happens between different tasks.
OS Threads vs Tokio Tasks
An OS thread has its own stack (typically 2–8 MB), is scheduled by the kernel, and context-switching between threads costs microseconds. Spawning 10,000 threads is impractical — the memory overhead alone would be 20–80 GB.
A Tokio task is a lightweight state machine (~few hundred bytes) scheduled cooperatively by the Tokio runtime. You can spawn hundreds of thousands without breaking a sweat. The trade-off: tasks must cooperate by yielding at .await points. An OS thread can be preempted mid-computation by the kernel; a Tokio task cannot.
In our blockchain node, each peer connection gets its own Tokio task (not its own OS thread). With 50 peers, that's 50 tasks multiplexed across 4–8 OS threads — efficient, lightweight, and the reason Tokio can handle thousands of connections where a thread-per-connection model would fall over.

The async model interleaves work from many peers onto a few threads. When Peer A's read suspends at .await (waiting for bytes), the worker thread immediately picks up work from another task. No CPU time is wasted waiting.
CPU-Bound vs IO-Bound Work
This distinction determines where you run each piece of work:
IO-bound work spends most of its time waiting — for network data, disk reads, database queries. This is where async/.await shines. While one task waits, the runtime schedules another. Our peer message handling, transaction relay, and block propagation are all IO-bound.
CPU-bound work keeps the processor busy continuously — hashing, encryption, proof-of-work computation. Async provides no benefit here because there's no waiting to interleave. Worse, a CPU-bound loop without .await points starves other tasks on the same worker thread.
// BAD: CPU-bound work directly on the async runtime.
// This loop never yields — no .await points — so the worker
// thread running this task can't service ANY other tasks
// (timers, accepts, channel reads) until mining finishes.
async fn mine_block_bad(header: &[u8], difficulty: u32) -> (u64, Vec<u8>) {
let mut nonce = 0u64;
loop {
let hash = sha256(header, nonce);
if leading_zeros(&hash) >= difficulty {
return (nonce, hash);
}
nonce += 1;
// No .await — this worker thread is monopolized
}
}
// GOOD: Yield periodically so other tasks can run,
// OR move to spawn_blocking / a dedicated thread.
async fn mine_block_good(header: &[u8], difficulty: u32) -> (u64, Vec<u8>) {
let mut nonce = 0u64;
loop {
// Check 10,000 nonces, then yield
for _ in 0..10_000 {
let hash = sha256(header, nonce);
if leading_zeros(&hash) >= difficulty {
return (nonce, hash);
}
nonce += 1;
}
// Yield to the runtime — other tasks get a chance to run
tokio::task::yield_now().await;
}
}
In our blockchain implementation, mining runs in an async context but internally yields periodically and checks the cancellation flag. The alternative (and arguably cleaner approach for pure CPU work) is tokio::task::spawn_blocking(), which we discuss later.
Cooperative Scheduling and the .await Contract
Tokio uses cooperative scheduling: tasks voluntarily yield control at .await points. Unlike OS threads, which the kernel can preempt at any instruction, Tokio tasks run uninterrupted between .awaits.
This has a crucial implication: the code between two .await points runs atomically from the runtime's perspective. If you hold a std::sync::MutexGuard across an .await, you're holding a lock while the task might be suspended for an unpredictable duration — and because MutexGuard is !Send, the compiler will actually prevent this in many cases. Tokio provides tokio::sync::Mutex, which is .await-aware and safe to hold across yield points, but it has its own costs (it's an async lock, so acquiring it may itself yield).
In our blockchain node, we're careful about this. The peer set (GLOBAL_NODES) uses std::sync::RwLock, not tokio::sync::RwLock, because we never hold the lock across an .await — every access is a quick read-or-write followed by an immediate drop. This is faster than the async alternative for short critical sections.
Send + 'static: Why tokio::spawn Has Bounds
Every tokio::spawn call requires the future to be Send + 'static. These bounds exist because of how the runtime works:
Send — the task might be started on one worker thread, suspended at an .await, and resumed on a different worker thread. Any data the task holds must be safe to move between threads. This is why you can't spawn a task that captures a Rc<T> (which is !Send) — you need Arc<T> instead.
'static — the spawned task has no guaranteed relationship with the spawner's lifetime. The spawner might complete while the task is still running (that's exactly what fire-and-forget means). So the task can't borrow from the spawner's stack — it must own all its data.
In practice, this means you'll clone data before spawning. When our node relays a transaction to peers (Pattern 3 below), we clone the NodeContext, copy the SocketAddr, and clone the transaction — because the spawned task must own everything it touches:
let context = self.clone(); // NodeContext is cheap to clone (Arc inside)
let addr_copy = *addr_from; // Copy the SocketAddr (it's Copy)
let tx = utxo.clone(); // Clone the transaction data
tokio::spawn(async move { // 'move' transfers ownership into the task
let _ = context.submit_transaction_for_mining(&addr_copy, tx).await;
});
If you've ever fought the compiler over "borrowed value does not live long enough" in a tokio::spawn call, this is why. The fix is almost always: clone the data or wrap it in Arc. The cost of an Arc clone is a single atomic increment — negligible compared to the network I/O the task will perform.
The Wire Protocol: Gossip and Fetch
With the mental model in place, let's look at what messages actually flow through the system. Bitcoin's P2P protocol uses a three-step gossip-and-fetch strategy to minimize bandwidth:

Peers announce what they have by sharing only the hash (the gossip phase). If the receiver doesn't already have that hash, it requests the full object (the fetch phase). This avoids sending full blocks to peers that already have them.
In our implementation, every message on the wire is a variant of a single Rust enum:
#[derive(Debug, Serialize, Deserialize)]
pub enum Package {
// Block and transaction relay
Block { addr_from: SocketAddr, block: Vec<u8> },
Tx { addr_from: SocketAddr, transaction: Vec<u8> },
// Gossip-and-fetch protocol
Inv { addr_from: SocketAddr, op_type: OpType, items: Vec<Vec<u8>> },
GetData { addr_from: SocketAddr, op_type: OpType, id: Vec<u8> },
GetBlocks { addr_from: SocketAddr },
// Peer discovery and versioning
Version { addr_from: SocketAddr, version: usize, best_height: usize },
KnownNodes { addr_from: SocketAddr, nodes: Vec<SocketAddr> },
// Admin operations (local queries, not part of P2P protocol)
AdminNodeQuery { addr_from: SocketAddr, query_type: AdminNodeQueryType },
// ...
}
This enum is the complete vocabulary of peer-to-peer communication. Every TCP message deserializes into one of these variants, and the dispatcher pattern-matches on it to route to the correct handler. The addr_from field on every variant lets the receiver know who sent the message — critical for relay logic that must avoid sending data back to its source.
Pattern 1: The Server Loop with tokio::select!
The first concurrency challenge is multiplexing two independent concerns: accepting new peer connections and listening for a shutdown signal. tokio::select! lets us race two futures against each other in a loop:
pub async fn run_with_shutdown(
&self,
addr: &SocketAddr,
mut shutdown: tokio::sync::broadcast::Receiver<()>,
) {
let listener = TcpListener::bind(addr)
.await
.expect("Failed to bind TCP listener");
// Bootstrap: announce ourselves to the network
if !addr.eq(&CENTRAL_NODE) {
let height = self.node_context
.get_blockchain_height().await
.expect("Blockchain read error");
send_version(&CENTRAL_NODE, height).await;
}
// Main event loop: accept connections OR shut down,
// whichever happens first on each iteration.
loop {
tokio::select! {
// Branch 1: shutdown signal arrived.
// The broadcast channel fires when the operator
// sends SIGINT or the orchestrator calls shutdown.
_ = shutdown.recv() => {
info!("Shutdown signal received");
break;
}
// Branch 2: a new peer connected.
// We accept and immediately spawn a dedicated
// task to handle this peer's message stream.
accept_result = listener.accept() => {
match accept_result {
Ok((stream, _peer_addr)) => {
let ctx = self.node_context.clone();
tokio::spawn(async move {
if let Err(e) =
process_stream(ctx, stream).await
{
error!("Peer handler error: {}", e);
}
});
}
Err(e) => error!("Accept error: {}", e),
}
}
}
}
}
The key insight: tokio::select! doesn't poll both branches simultaneously — it awaits whichever completes first, executes that branch, and then loops. If a shutdown signal arrives while we're waiting for a connection, we break immediately. If a connection arrives while no shutdown has been requested, we handle it and loop back. This pattern ensures the node can shut down mid-accept without waiting for a timeout.
Cancellation Safety: Why select! Requires Care
There's a subtlety that bites many Tokio users: when one branch of select! completes, the other branches' futures are dropped. This is fine for listener.accept() and shutdown.recv() — both are cancellation-safe, meaning dropping them mid-await loses no data. But not all futures are safe to cancel this way.
Consider what would happen if instead of listener.accept(), one of our branches was stream.read_exact(&mut buf) — a partially-completed read. If the other branch wins the race, the read future gets dropped, and however many bytes were already read into buf are silently lost. The next time we call read_exact, we'd start from scratch, missing those bytes. This is the class of bugs that async Rust's cancellation model can produce.
The Tokio documentation marks each method's cancellation safety explicitly. When building your own select! loops, check each branch: accept() is safe, recv() is safe, but read_exact(), write_all(), and many buffered I/O operations are not. If you need a cancel-unsafe operation in a select! branch, wrap it in a tokio::spawn — spawned tasks are not cancelled when their JoinHandle is dropped, only when explicitly aborted.
Shutdown Signals: broadcast vs CancellationToken
Our implementation uses broadcast::Receiver<()> for shutdown coordination. This works, but the Tokio ecosystem has converged on a cleaner abstraction: CancellationToken from the tokio-util crate. Here's how the same server loop would look:
use tokio_util::sync::CancellationToken;
pub async fn run_with_shutdown(
&self,
addr: &SocketAddr,
shutdown: CancellationToken,
) {
let listener = TcpListener::bind(addr).await.unwrap();
loop {
tokio::select! {
_ = shutdown.cancelled() => {
info!("Shutdown signal received");
break;
}
accept_result = listener.accept() => {
// ... same as before
}
}
}
}
CancellationToken has two advantages over broadcast channels. First, it's cheaply cloneable — you can hand a clone to every subsystem without worrying about channel capacity or lagged receivers. Second, it supports hierarchical cancellation: you can create child tokens that cancel when the parent cancels, but cancelling a child doesn't cancel the parent. This maps naturally to subsystem lifecycle — shutting down the mining loop shouldn't shut down the API server, but shutting down the entire node should shut down everything.
In production Tokio services, CancellationToken combined with tokio::signal::ctrl_c() is the standard pattern for graceful shutdown. Our broadcast channel approach is functionally equivalent for a single-level shutdown, but CancellationToken scales better as systems grow more complex.
Pattern 2: One Task Per Connection
Every accepted connection gets its own tokio::spawned task. This is the standard concurrent server pattern, but what happens inside that task is where things get interesting.
The message dispatcher reads a continuous stream of JSON messages from the TCP connection, deserializes each into a Package, and routes it:
pub async fn process_stream(
node_context: NodeContext,
stream: TcpStream,
) -> Result<()> {
let reader = BufReader::new(stream);
let mut deserializer =
serde_json::Deserializer::from_reader(reader);
loop {
match serde_json::Value::deserialize(&mut deserializer) {
Ok(value) => {
match serde_json::from_value::<Package>(value) {
Ok(pkg) => {
// Route by variant — each arm calls into
// a different subsystem via NodeContext
if let Err(e) = match pkg {
Package::Tx { addr_from, transaction } => {
let tx = Transaction::deserialize(&transaction)?;
node_context
.process_transaction(&addr_from, tx)
.await
.map(|_| ())
}
Package::Block { addr_from, block } => {
let blk = Block::deserialize(&block)?;
// Cancel any in-progress mining —
// a competing block just arrived
cancel_current_mining();
node_context.add_block(&blk).await
}
Package::Inv { addr_from, op_type, items } => {
handle_inv(
&node_context, &addr_from,
op_type, items
).await
}
Package::GetData { addr_from, op_type, id } => {
handle_get_data(
&node_context, &addr_from,
op_type, id
).await
}
Package::Version { addr_from, .. } => {
GLOBAL_NODES.add_node(addr_from).map(|_| ())
}
_ => Ok(()),
} {
error!("Handler error: {}", e);
}
}
Err(e) => {
error!("Deserialization error: {}", e);
break;
}
}
}
// Peer disconnected cleanly
Err(e) if e.is_eof() => break,
// Malformed data — close the connection
Err(e) => {
error!("Stream read error: {}", e);
break;
}
}
}
Ok(())
}
Notice the cancel_current_mining() call inside the Package::Block handler. When a peer sends us a new block, our own in-progress mining is now working on a stale tip. We set an atomic flag to abort the proof-of-work computation immediately. We'll look at the mining concurrency guard in detail later.
The match pkg { ... } block is the message router — the equivalent of a network protocol handler. Every incoming message has exactly one code path, and the compiler enforces exhaustiveness. If someone adds a new Package variant and forgets to handle it here, the code won't compile.
Pattern 3: Fire-and-Forget Broadcasting with tokio::spawn
When a transaction is accepted into the mempool, the node needs to announce it to all peers via INV messages. But this broadcast is not on the critical path — the caller (the API handler or peer connection) shouldn't wait for every peer to acknowledge the relay before returning.
This is where tokio::spawn shines as a fire-and-forget mechanism:
pub async fn process_transaction(
&self,
addr_from: &SocketAddr,
utxo: Transaction,
) -> Result<String> {
// 1. Duplicate check — fast, synchronous
if transaction_exists_in_pool(&utxo) {
return Err(BtcError::TransactionAlreadyExistsInMemoryPool(
utxo.get_tx_id_hex(),
));
}
// 2. Accept into mempool (marks UTXO outputs as "in mempool"
// to prevent double-spending)
add_to_memory_pool(utxo.clone(), &self.blockchain).await?;
// 3. Background: relay to peers + maybe trigger mining.
// tokio::spawn detaches this work from the current task.
// The caller gets the txid back immediately — they don't
// wait for relay or mining to complete.
let context = self.clone();
let addr_copy = *addr_from;
let tx = utxo.clone();
tokio::spawn(async move {
let _ = context
.submit_transaction_for_mining(&addr_copy, tx)
.await;
});
// Return the transaction ID to the caller while
// relay and mining happen in the background
Ok(utxo.get_tx_id_hex())
}
The let _ = inside the spawned task is deliberate. If relay fails (a peer is unreachable), we log it and move on. This is correct for a gossip protocol — if one peer doesn't receive the INV, another peer will relay it later. The alternative — propagating errors back to the caller — would mean a single unreachable peer could block transaction admission.
The same fire-and-forget pattern appears in block broadcasting after mining:
pub async fn broadcast_new_block(block: &Block) -> Result<()> {
let my_addr = GLOBAL_CONFIG.get_node_addr();
let nodes = GLOBAL_NODES.get_nodes()?;
for node in nodes {
if node.get_addr() != my_addr {
let addr = node.get_addr();
let hash = block.get_hash_bytes();
// Each peer gets its own spawned task.
// If peer 3 is slow, peers 1 and 2 still
// get notified immediately.
tokio::spawn(async move {
send_inv(&addr, OpType::Block, &[hash]).await;
});
}
}
Ok(())
}
Each peer announcement runs in its own task. A slow or disconnected peer doesn't delay announcements to other peers. This is a common pattern in distributed systems: fan-out with independent failure domains.
When Fire-and-Forget Is Wrong
It's worth noting when this pattern is not appropriate. Fire-and-forget works for gossip because the protocol is self-healing — if peer B misses an INV from peer A, peer C will send it later. But for operations where you need confirmation (like writing to a database, sending an email, or completing a financial transaction), dropping the JoinHandle without awaiting it means you'll never know if the operation succeeded. For those cases, collect the handles and await them:
// When you need to know the results:
let mut handles = Vec::new();
for peer in &peers {
let addr = peer.get_addr();
let data = payload.clone();
handles.push(tokio::spawn(async move {
send_data(&addr, data).await
}));
}
// Wait for all broadcasts and collect failures
let results = futures::future::join_all(handles).await;
let failures: Vec<_> = results.iter()
.filter(|r| r.as_ref().map_or(true, |inner| inner.is_err()))
.collect();
if !failures.is_empty() {
warn!("{} peers failed to acknowledge", failures.len());
}
The choice between fire-and-forget and awaited fan-out is a design decision about your system's consistency requirements, not a technical limitation.
Pattern 4: Atomic Guards for Mining Concurrency
Mining is the most interesting concurrency challenge. Proof-of-work can run for seconds. During that time, a competing block might arrive from a peer, making our computation worthless. We also need to prevent two threads from mining the same block simultaneously (which could happen if multiple transactions trigger the mining threshold at nearly the same time).
We solve both problems with AtomicBool flags:
static MINING_IN_PROGRESS: AtomicBool = AtomicBool::new(false);
static MINING_CANCELLED: AtomicBool = AtomicBool::new(false);
pub async fn process_mine_block(
txs: Vec<Transaction>,
blockchain: &BlockchainService,
) -> Result<Block> {
// Guard: prevent concurrent mining.
// compare_exchange atomically checks "is it false?"
// and sets it to true. If another thread already set it
// to true, we get Err and bail out.
if MINING_IN_PROGRESS
.compare_exchange(false, true, Ordering::SeqCst, Ordering::SeqCst)
.is_err()
{
return Err("Mining already in progress".into());
}
// Reset the cancellation flag before starting
reset_mining_cancellation();
let result = async {
// Check if a competing block arrived between
// the trigger and now
if is_mining_cancelled() {
return Err("Mining cancelled: new block received".into());
}
// Proof-of-work: this is the expensive part.
// Internally, the PoW loop checks is_mining_cancelled()
// periodically to abort early if a competing block arrives.
let new_block = blockchain.mine_block(&txs).await?;
// CRITICAL: Once mine_block() returns successfully, the block
// is already in our local chain (tip updated, UTXO set modified).
// We MUST broadcast it. If we cancel here, we create a permanent
// fork — our chain has a block that no peer knows about.
// Remove confirmed transactions from the mempool
for tx in &txs {
remove_from_memory_pool(tx.clone(), blockchain).await;
}
// Announce the new block hash to all peers
broadcast_new_block(&new_block).await?;
Ok(new_block)
}
.await;
// Always release the mining lock, even on error.
// Without this, a failed mining attempt would
// permanently block all future mining.
MINING_IN_PROGRESS.store(false, Ordering::SeqCst);
result
}
Several things are worth unpacking here.
compare_exchange is not a mutex. A mutex would block the second caller until mining finishes. compare_exchange fails immediately — the second caller gets an error and moves on. This is correct behavior: if mining is already in progress with the current mempool contents, queuing a second mining attempt is wasteful.
The cancellation flag is checked at two points. Once before mining starts (to catch blocks that arrived during preparation), and periodically inside the PoW loop itself. When a peer sends us a Package::Block, the message handler calls cancel_current_mining(), which sets MINING_CANCELLED to true. The PoW loop checks this flag every N iterations and bails out early if set.
The "no cancel after creation" rule is critical. The comment in the code explains why: once mine_block() returns, the block has been written to our local chain. Our tip has advanced, our UTXO set has been updated. If we skip the broadcast, we create a fork — our chain has a block that no peer will ever request because they don't know its hash. This is a real distributed systems bug that wouldn't show up in unit tests but would cause chain divergence in production.
SeqCst ordering is the safe default. For two independent atomic flags that interact (in-progress and cancelled), sequential consistency ensures all threads see flag changes in the same order. Weaker orderings (Relaxed, Acquire/Release) could allow a thread to see the cancellation flag before the in-progress flag, leading to subtle race conditions. In practice, SeqCst has negligible performance overhead on x86 architectures (where all loads and stores are already strongly ordered), and the correctness guarantee is worth far more than any nanoseconds saved by weaker orderings.
A Deeper Look: Why Not tokio::sync::Mutex or CancellationToken?
You might wonder why we used raw AtomicBool flags instead of higher-level abstractions. There are three alternatives worth considering, each with trade-offs:
tokio::sync::Mutex<bool> would work, but it's overkill. A mutex provides mutual exclusion for a critical section — it says "only one task can enter this region at a time." Our mining guard doesn't need a critical section. It needs a non-blocking test: "is mining happening?" If yes, bail out immediately. compare_exchange expresses this intent directly without the overhead of lock acquisition.
CancellationToken (from tokio_util) would be a clean fit for the cancellation signal specifically. You'd create a new token before each mining attempt, pass it into the PoW loop, and call token.cancel() when a competing block arrives. The PoW loop would check token.is_cancelled() instead of our custom is_mining_cancelled() function. This is arguably better style — it's the ecosystem-standard way to express cooperative cancellation in Tokio — and it's what we'd use if we were starting fresh today.
tokio::sync::Notify could replace the cancellation flag with an async signal. The PoW loop would select! between the computation and notify.notified(). This integrates more naturally with async/await but makes the PoW loop itself async, which adds complexity for CPU-bound work.
We chose AtomicBool because it's the simplest primitive that solves the problem, requires no dependencies beyond std, and is obvious to anyone who's worked with concurrent code in any language. For a more complex cancellation protocol — say, with timeout deadlines or nested cancellation scopes — CancellationToken would be the better choice.
Pattern 5: The Coordination Façade
All of these concurrent subsystems — networking, mempool, mining, chainstate — need a single point of coordination. That's NodeContext:
#[derive(Clone, Debug)]
pub struct NodeContext {
blockchain: BlockchainService,
}
It's deliberately small. NodeContext owns a single dependency (the blockchain service handle) and reaches into global state for everything else: the mempool (GLOBAL_MEMORY_POOL), the peer set (GLOBAL_NODES), the mining flags (MINING_IN_PROGRESS). This design means NodeContext is cheap to Clone — it's just an Arc under the hood — which matters because every spawned task needs its own copy.
The façade pattern shows up in the transaction lifecycle. What looks like a single operation from the outside is actually a multi-step pipeline across several subsystems:

The caller (the REST API handler or peer connection) sees one async fn call. Behind the façade, the node is coordinating mempool admission, peer relay, and mining — each with its own concurrency model. The mempool uses an RwLock for thread-safe access. The peer set uses its own RwLock. Mining uses atomic flags. The façade hides this complexity behind a clean interface.
The Trade-off We Made: Blocking I/O in Async Tasks
There's one deliberate architectural compromise in this codebase that's worth discussing because it reflects a trade-off many real-world Rust projects face.
Our message parsing uses serde_json::Deserializer::from_reader(), which requires a synchronous std::io::Read implementor. Tokio's TcpStream implements AsyncRead, not Read. So in the server loop, we convert the Tokio stream to a standard library stream:
// Inside the spawned task for each connection:
match stream.into_std() {
Ok(std_stream) => {
let _ = std_stream.set_nonblocking(false);
process_stream(node_context, std_stream).await
}
// ...
}
This means each per-connection task uses blocking I/O on a Tokio worker thread. And this is where understanding Tokio's runtime architecture matters.
Why Blocking on a Worker Thread Is Dangerous (and When It's Not)
Tokio's multi-threaded runtime has a fixed pool of worker threads (by default, one per CPU core). Every tokio::spawned task runs on one of these workers. When a task blocks — calls a synchronous function that waits for I/O — it holds that worker thread hostage. No other task scheduled to that thread can make progress until the blocking call returns.
Alice Ryhl (a Tokio maintainer) puts it well: if you have 4 worker threads and 4 tasks are all blocking on synchronous I/O, your entire async runtime is frozen. Pending timers, pending accepts, pending channel reads — everything stops until one of those blocking calls finishes.
For our blockchain node, this is acceptable because the peer count is small (8–50 connections) and each connection spends most of its time waiting for the next message. With 4–8 CPU cores, we have enough workers to absorb a few blocked threads without starving the rest of the runtime.
But there's a better approach: tokio::task::spawn_blocking(). This API moves blocking work off the async worker pool onto a dedicated blocking thread pool that Tokio manages separately:
// Better: blocking I/O runs on the blocking thread pool,
// keeping async workers free for non-blocking tasks.
let ctx = self.node_context.clone();
let handle = tokio::runtime::Handle::current();
tokio::task::spawn_blocking(move || {
// This closure runs on a dedicated blocking thread.
// The async worker that spawned it is immediately
// available for other tasks.
// We use the captured handle to drive async calls
// (like node_context.add_block().await) from within
// the blocking context.
handle.block_on(async {
process_stream(ctx, std_stream).await
})
});
spawn_blocking is the correct tool when you must call synchronous APIs from async code. It's used heavily in the Rust ecosystem for file I/O (std::fs), CPU-bound computation (hashing, compression), and synchronous database drivers. The blocking thread pool has a much larger default limit (512 threads) precisely because blocked threads don't consume CPU — they're just waiting.
The Fully Async Alternative
For a production node aiming at scale, the right path forward would eliminate the blocking from_reader entirely:
use tokio::io::{AsyncBufReadExt, BufReader};
// Async message framing: read one JSON message per line
async fn process_stream_async(
node_context: NodeContext,
stream: tokio::net::TcpStream,
) -> Result<()> {
let reader = BufReader::new(stream);
let mut lines = reader.lines();
while let Some(line) = lines.next_line().await? {
let pkg: Package = serde_json::from_str(&line)?;
// ... dispatch pkg to handlers
}
Ok(())
}
This approach requires newline-delimited JSON (each message on one line), which is a minor protocol change. The benefit: zero blocking calls, all I/O is truly asynchronous, and the runtime can efficiently multiplex thousands of connections across a handful of worker threads. Libraries like tokio-serde and tokio-util's LengthDelimitedCodec provide battle-tested framing implementations.
We chose simplicity over scalability because a blockchain P2P network typically has 8–50 peers, not 10,000. The from_reader API is mature, battle-tested, and requires zero framing logic. For this use case, that trade-off is correct. For yours, it might not be — and that's a judgment call you should make deliberately rather than by default.
Putting It All Together: A Transaction's Journey
To see how all these patterns compose, trace a single transaction from arrival to mining:

Five patterns, one transaction flow. The server loop (select!) accepted the connection. The per-connection task deserialized and routed the message. Fire-and-forget spawning handled relay without blocking the caller. Atomic guards prevented concurrent mining. And the façade (NodeContext) coordinated it all behind a single async fn.
Key Takeaways
If you're building a concurrent system in Rust with Tokio — whether it's a blockchain node, a game server, or a distributed cache — here are the patterns that transferred:
tokio::select! is your event multiplexer, but respect cancellation safety. Use it whenever a loop needs to respond to multiple independent event sources. But check each branch: when one branch wins, the others are dropped. If a dropped future loses partially-completed work (like write_all that's written half the buffer), you have a bug. The Tokio docs mark each method's cancellation safety — read them.
tokio::spawn serves two roles — know which one you need. As an isolation boundary (one task per connection), it ensures one peer's slow response doesn't block another. As a fire-and-forget mechanism (broadcasting), it detaches background work from the critical path. But fire-and-forget is only safe when the operation is idempotent or self-healing (like gossip). For operations that must succeed, collect and await the JoinHandles.
Atomic flags beat mutexes for simple boolean coordination. When you need "is mining happening right now?" — not "wait until mining finishes" — AtomicBool with compare_exchange is lighter weight, non-blocking, and expresses intent more clearly than Mutex<bool>. For more complex cancellation scenarios, CancellationToken from tokio-util is the ecosystem standard.
Never block a Tokio worker thread without knowing the cost. If you must call synchronous APIs (file I/O, blocking database drivers, CPU-heavy computation), use tokio::task::spawn_blocking() to move the work off the async worker pool. Blocking a worker thread silently degrades the entire runtime's throughput. For a handful of connections it's survivable; at scale it's fatal.
Façades simplify async coordination. A thin struct that delegates to subsystems lets you change the concurrency model of any individual subsystem without affecting callers. NodeContext could switch its mempool from a global RwLock to an actor-based channel, and no caller would need to change.
Design for the concurrency you have, not the concurrency you imagine. We used blocking I/O in tokio::spawn tasks because our peer count is small and the simplicity gain was real. Premature optimization toward fully-async I/O would have added framing complexity for no measurable benefit. Know your system's actual concurrency profile, make the simplest choice that works, and document the scaling limit so future you knows when to revisit.
Explore the Source Code
The complete networking and node orchestration implementation is open source:
Full repository: github.com/bkunyiha/rust-blockchain
Key files:
net_processing.rs — Message dispatcher and send primitives
server.rs — TCP server loop with graceful shutdown
miner.rs — Mining pipeline with atomic concurrency guards
txmempool.rs — Transaction mempool admission and removal
context.rs — NodeContext façade
This post is adapted from Rust Blockchain: A Full-Stack Implementation Guide — a 33-chapter book covering Axum, Iced, Tauri 2, Tokio, SQLCipher, Docker, and Kubernetes through one cohesive project.
Available now on Amazon (paperback + Kindle + hardcover), Gumroad (PDF + EPUB), and Leanpub (pay what you want).
Free resource: Clone the Starter Template
Follow buildwithrust.com for weekly posts on building production systems in Rust.